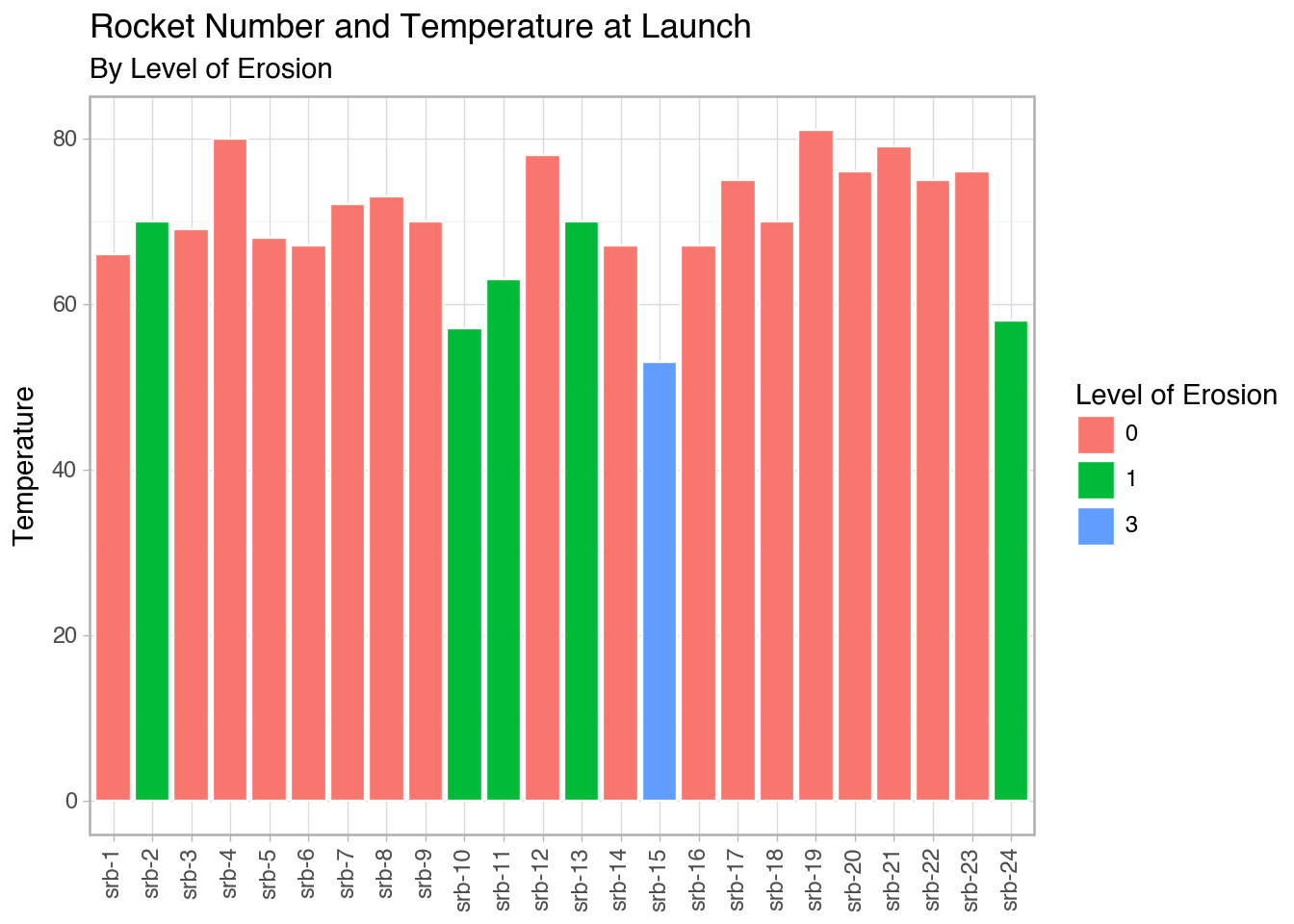
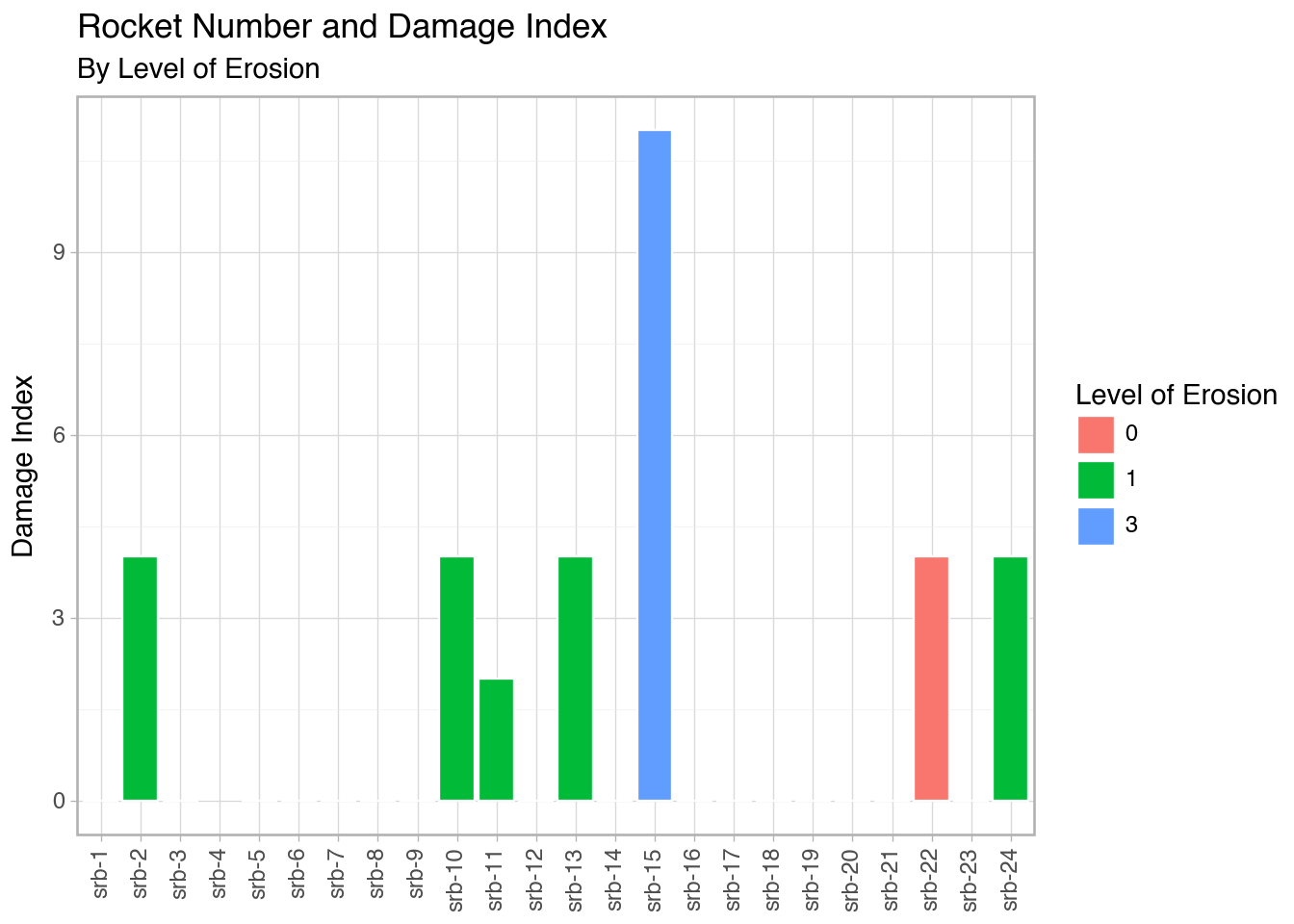
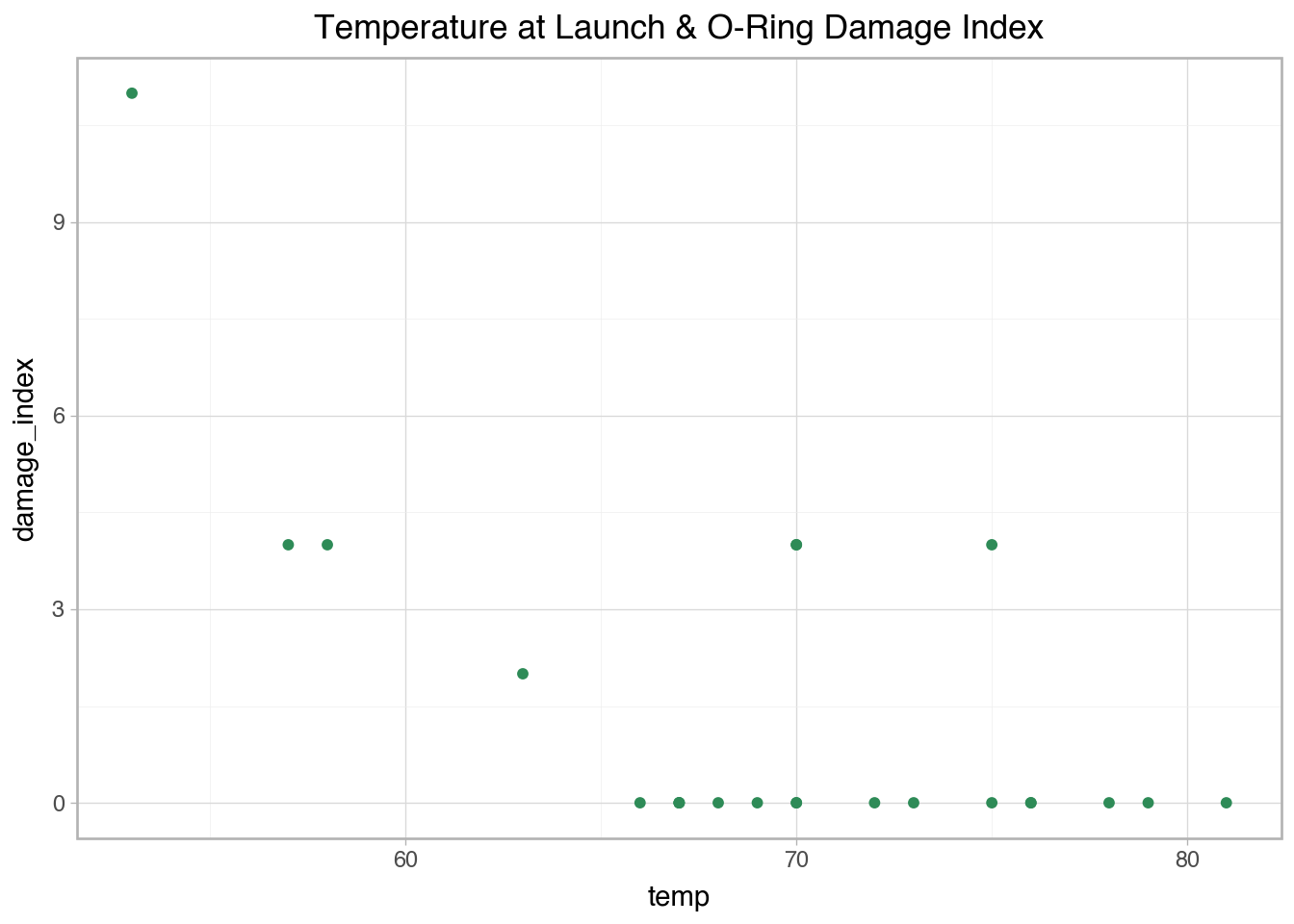
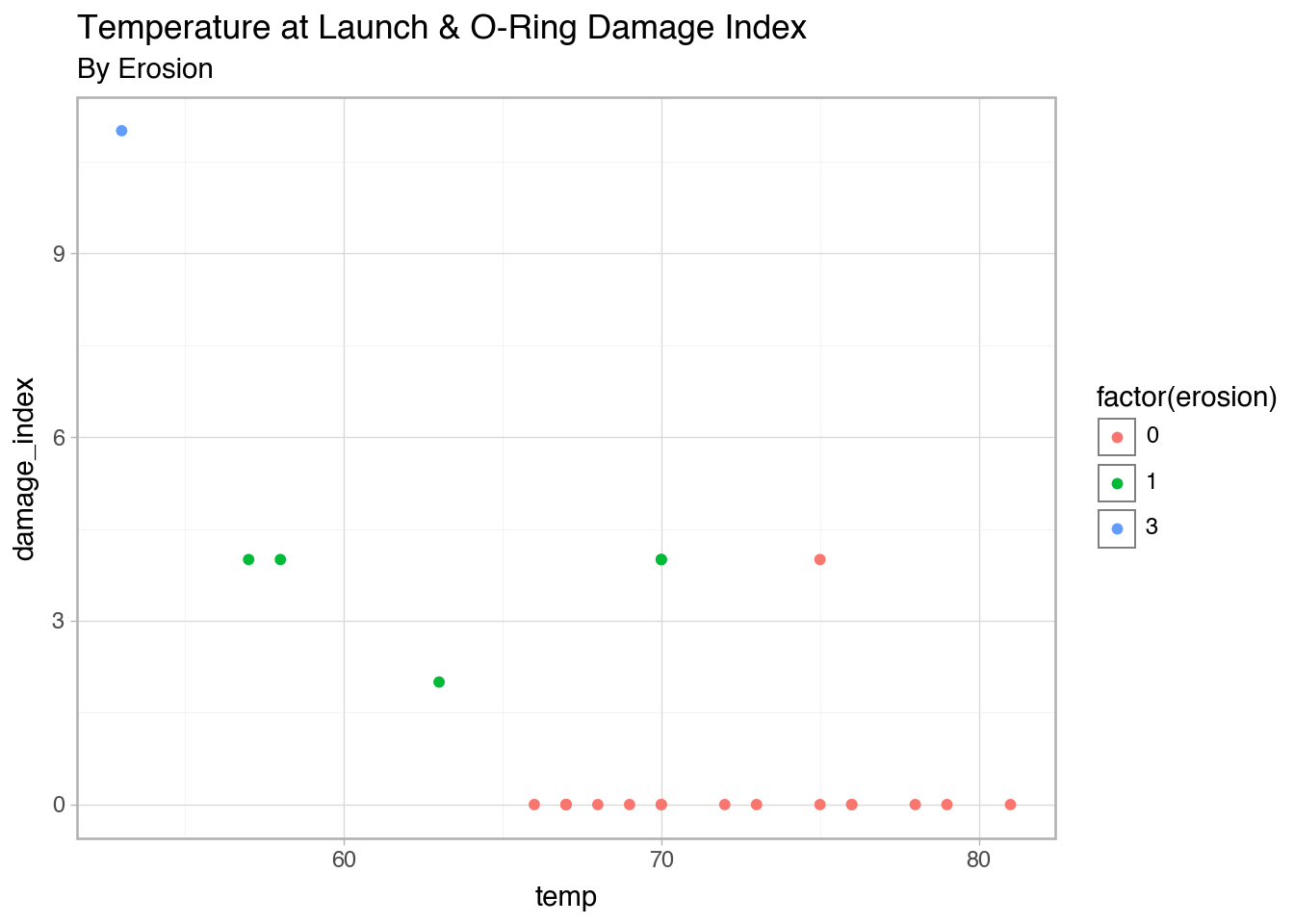
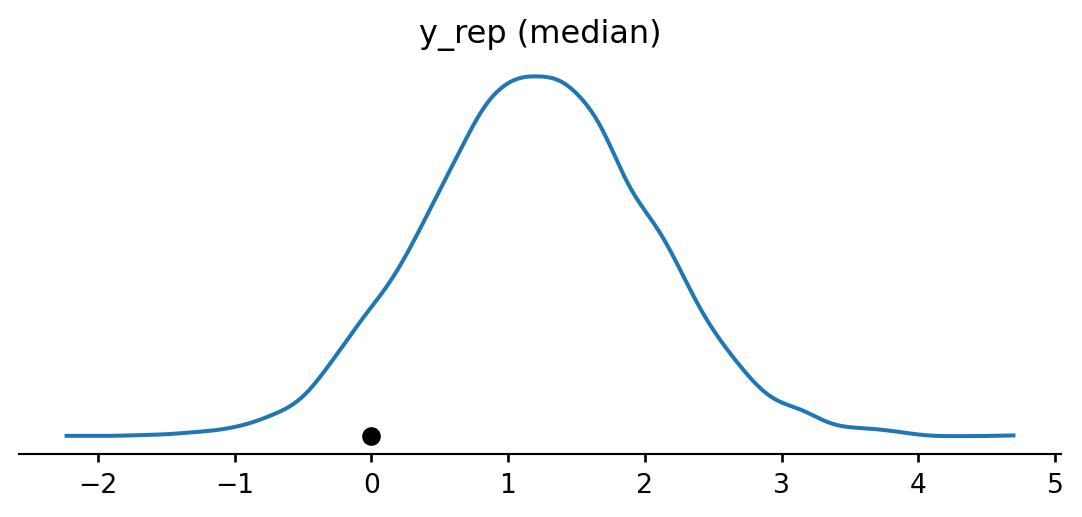
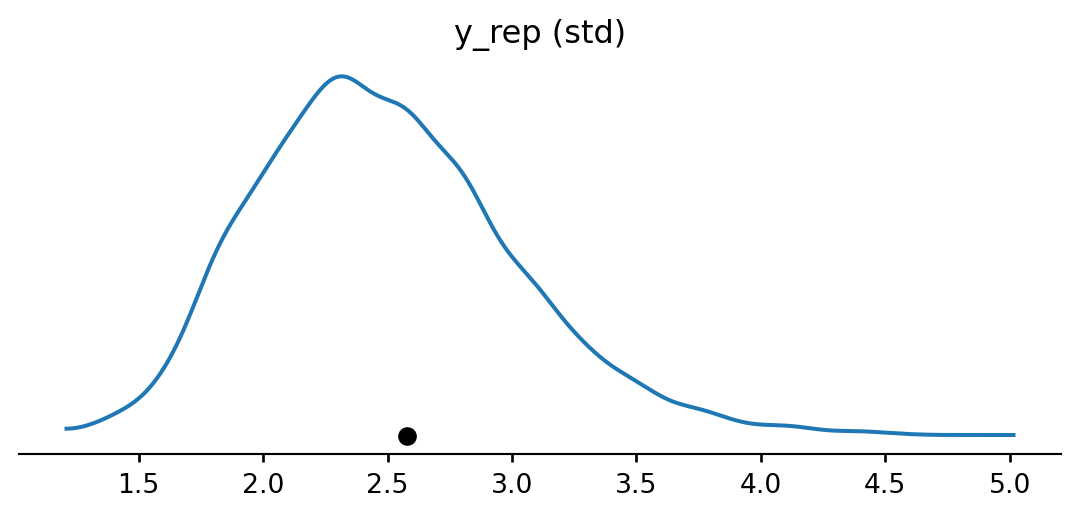
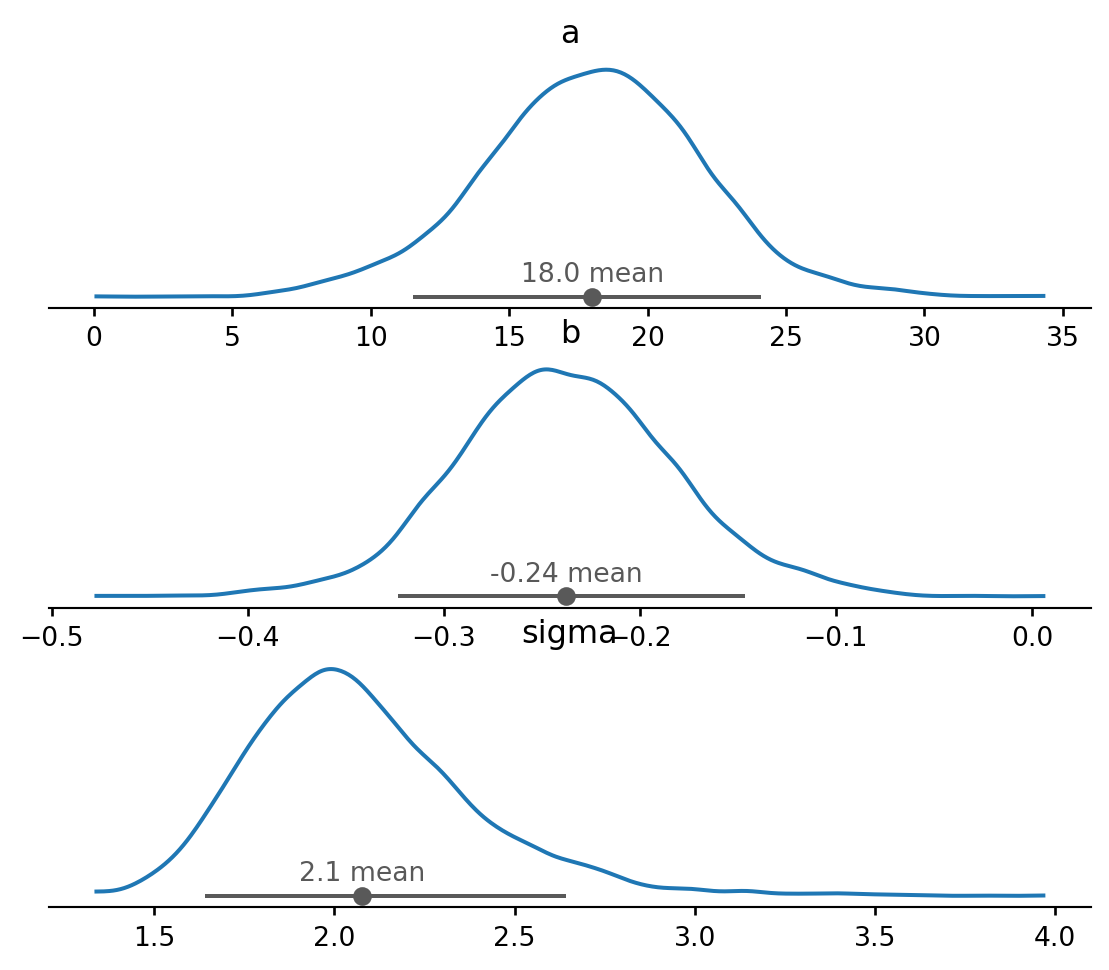
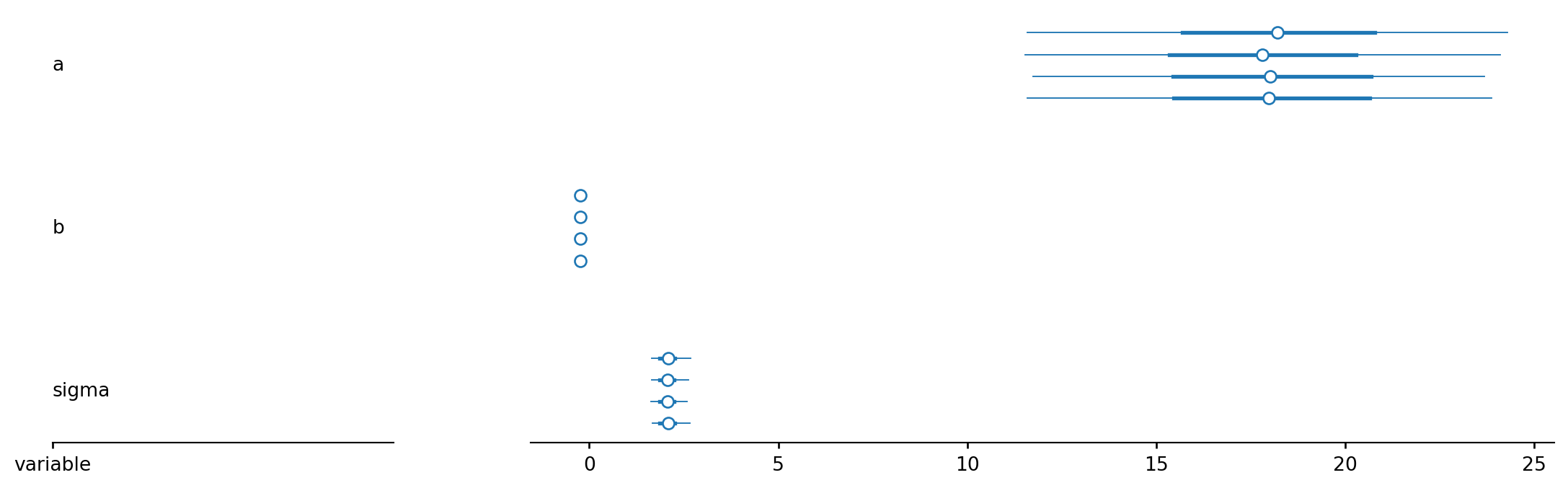
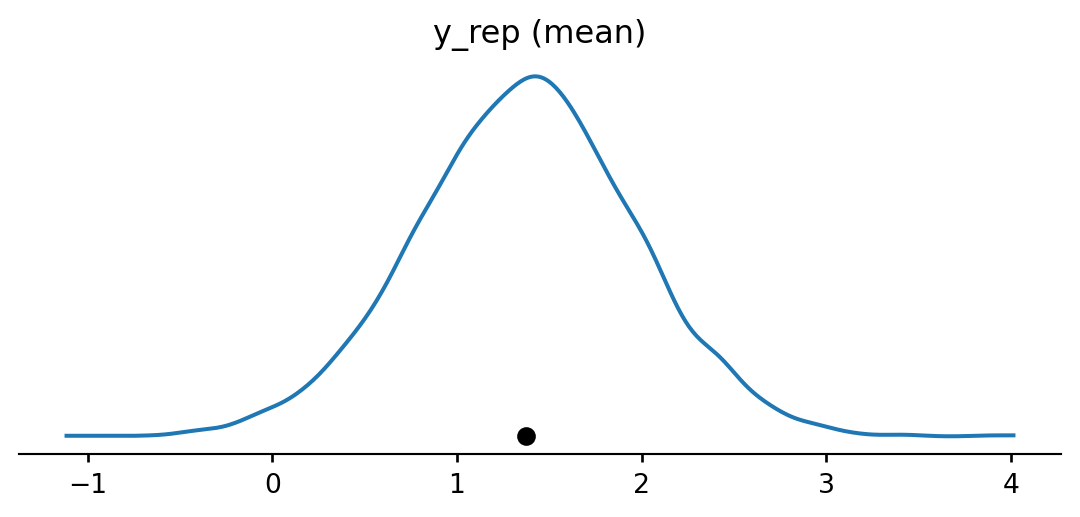
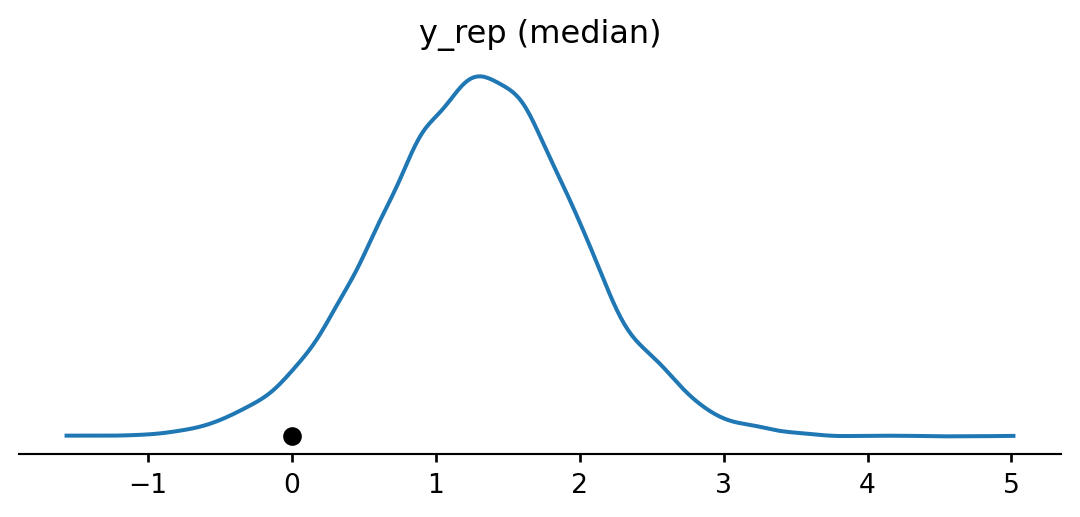
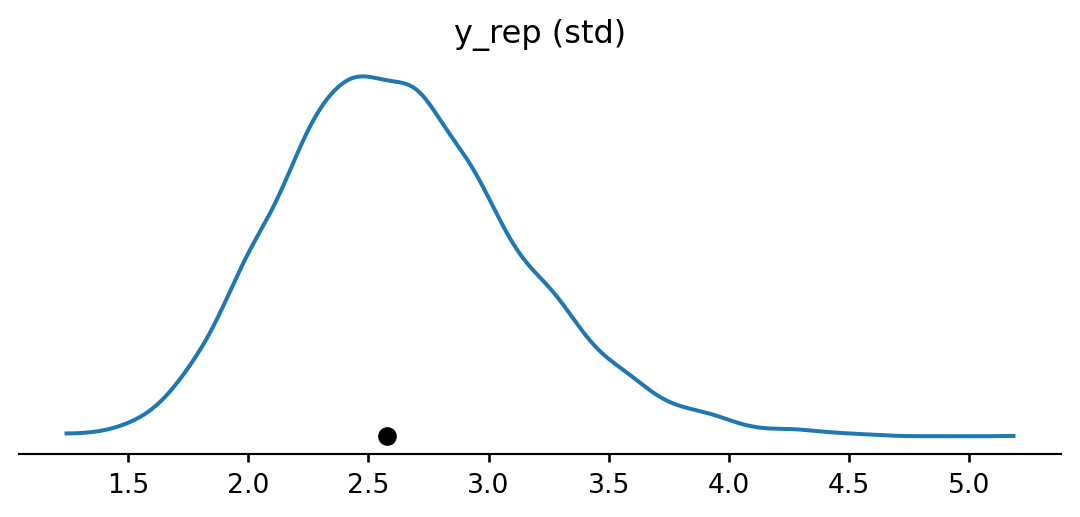
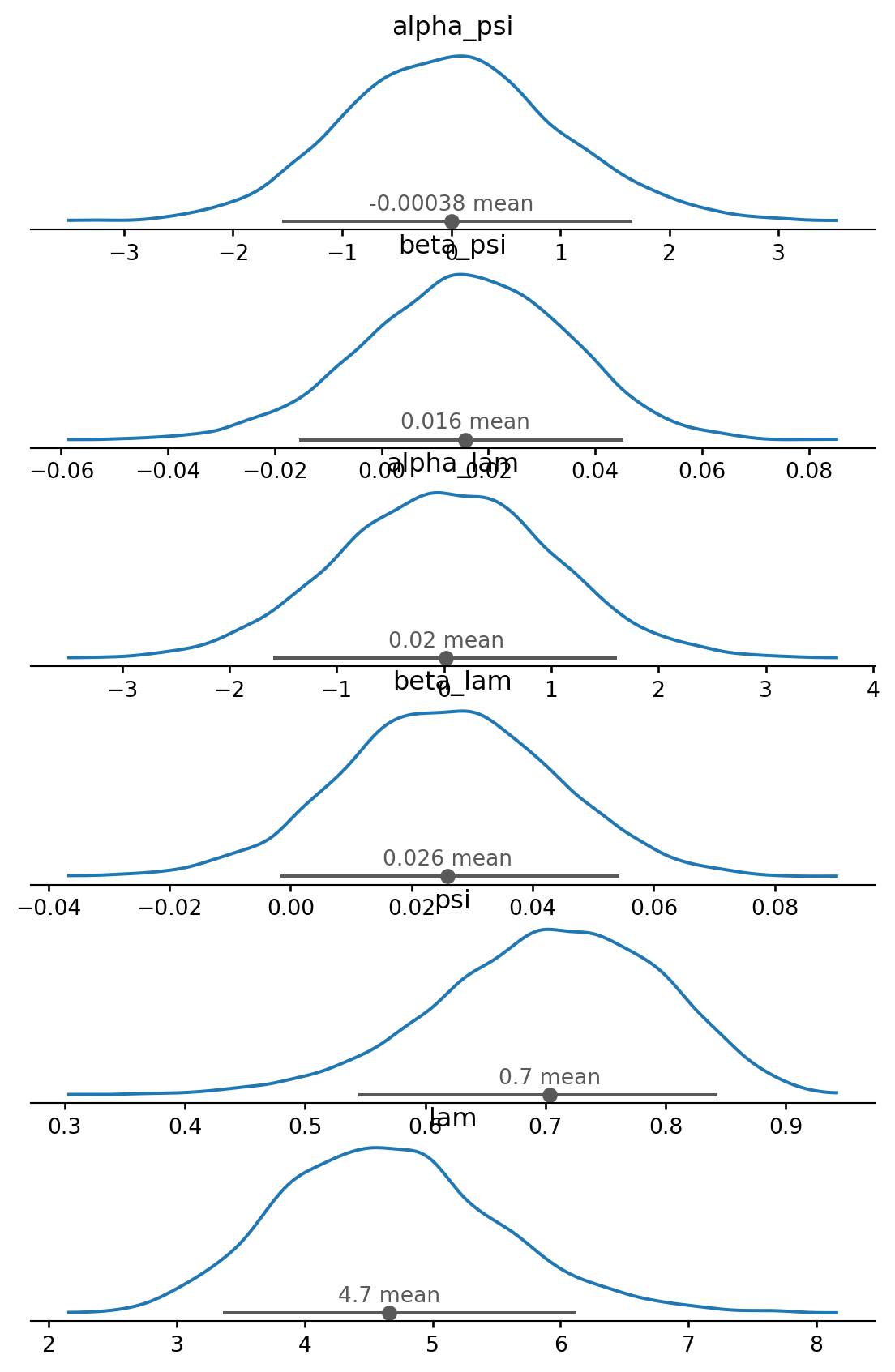
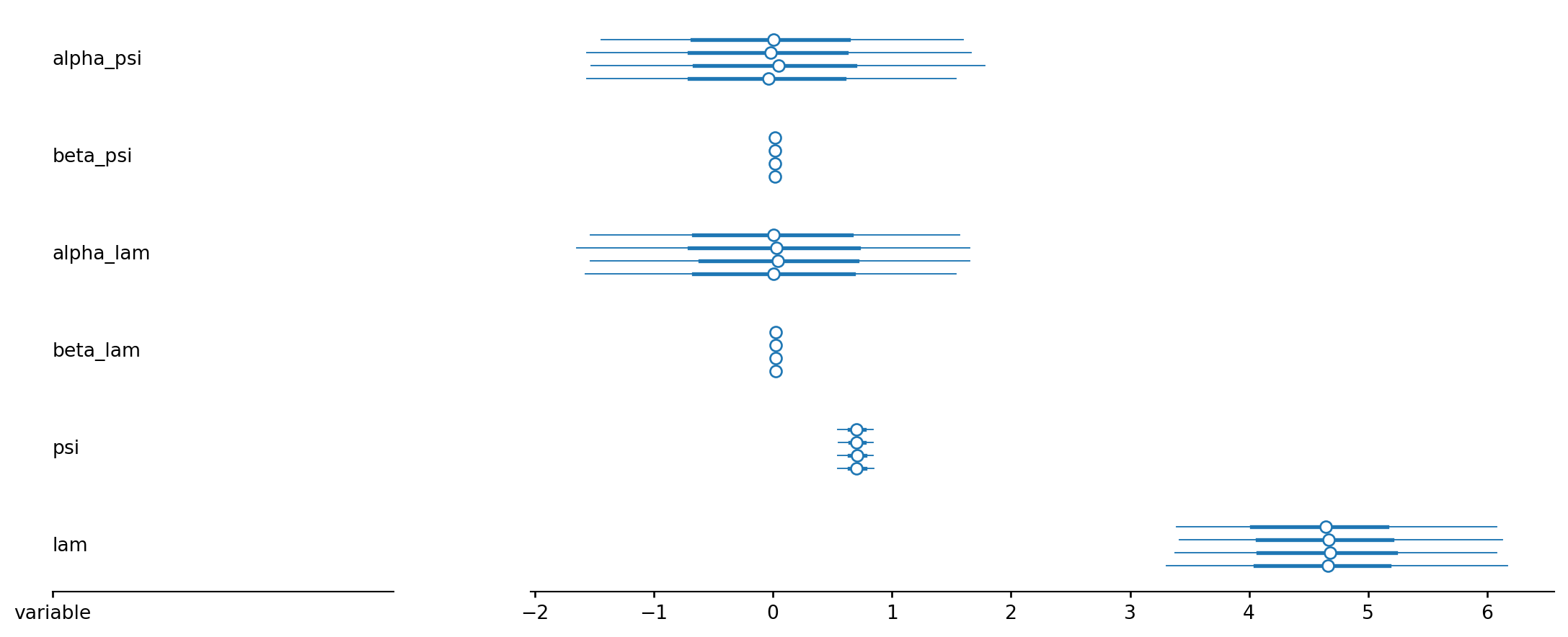
space = pd.DataFrame({'flight_number': ['51-C', '41-B', '61-C', '41-C', '1', '6', '51-A', '51-D', '5', '3', '2', '9', '41-D', '51-G', '7', '8', '51-B', '61-A', '51-I', '61-B', '41-G', '51-J', '4', '51-F'],
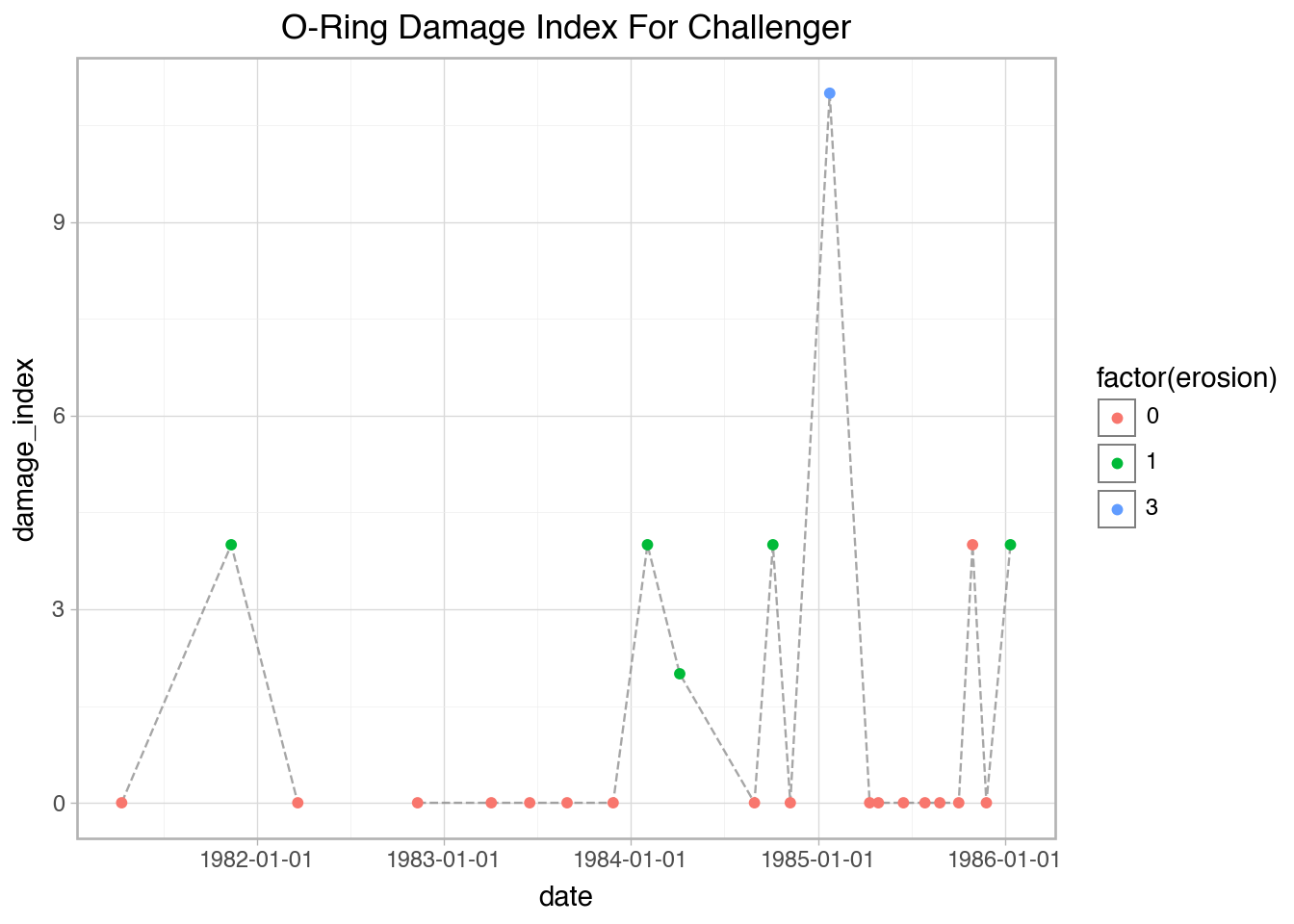
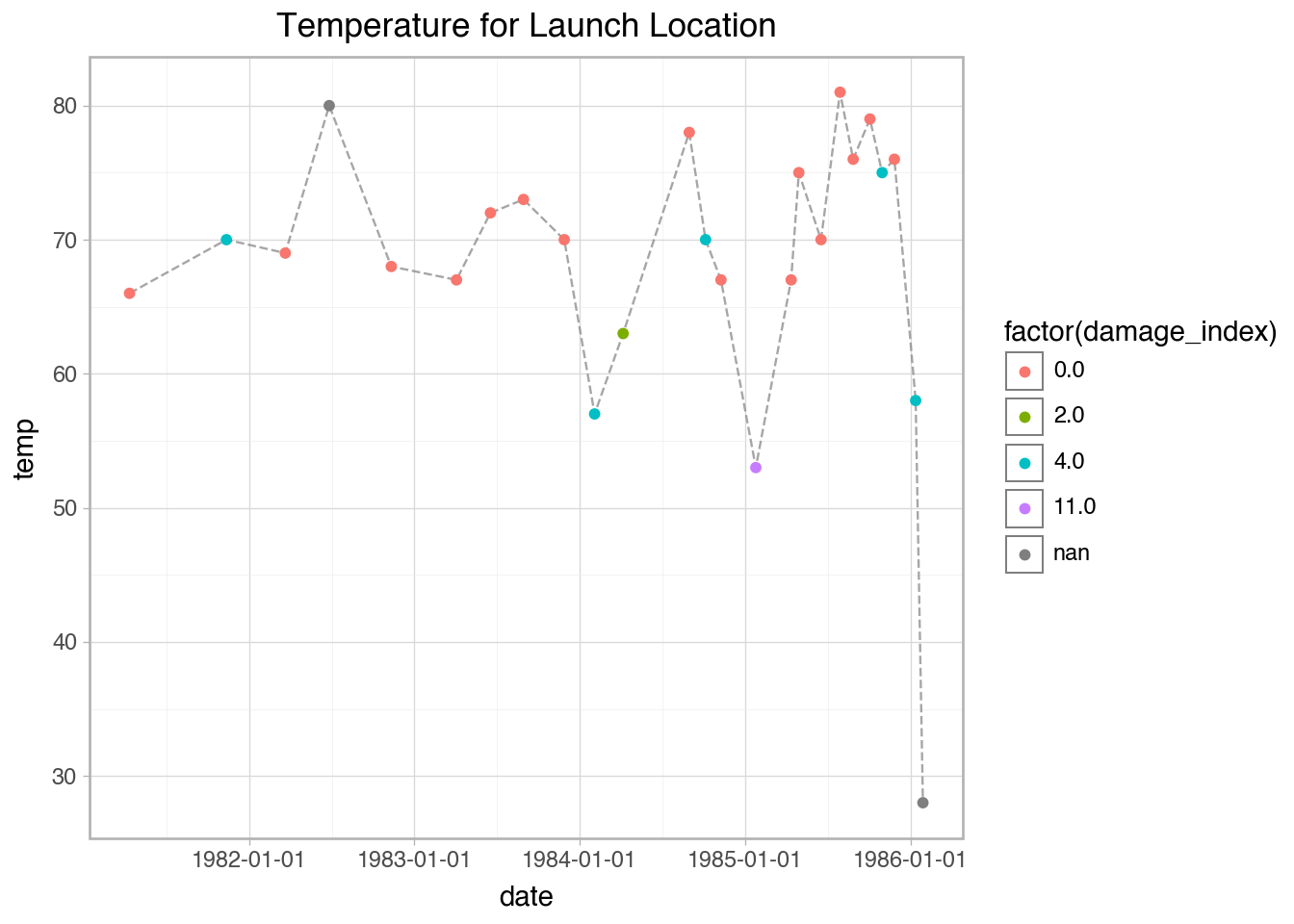
'date': ['01-24-85', '02-03-84', '01-12-86', '04-06-84', '04-12-81', '04-04-83', '11-08-84', '04-12-85', '11-11-82', '03-22-82', '11-12-81', '11-28-83', '08-30-84', '06-17-85', '06-18-83', '08-30-83', '04-29-85', '10-30-85', '08-27-85', '11-26-85', '10-05-84', '10-03-85', '06-27-82', '07-29-85'],
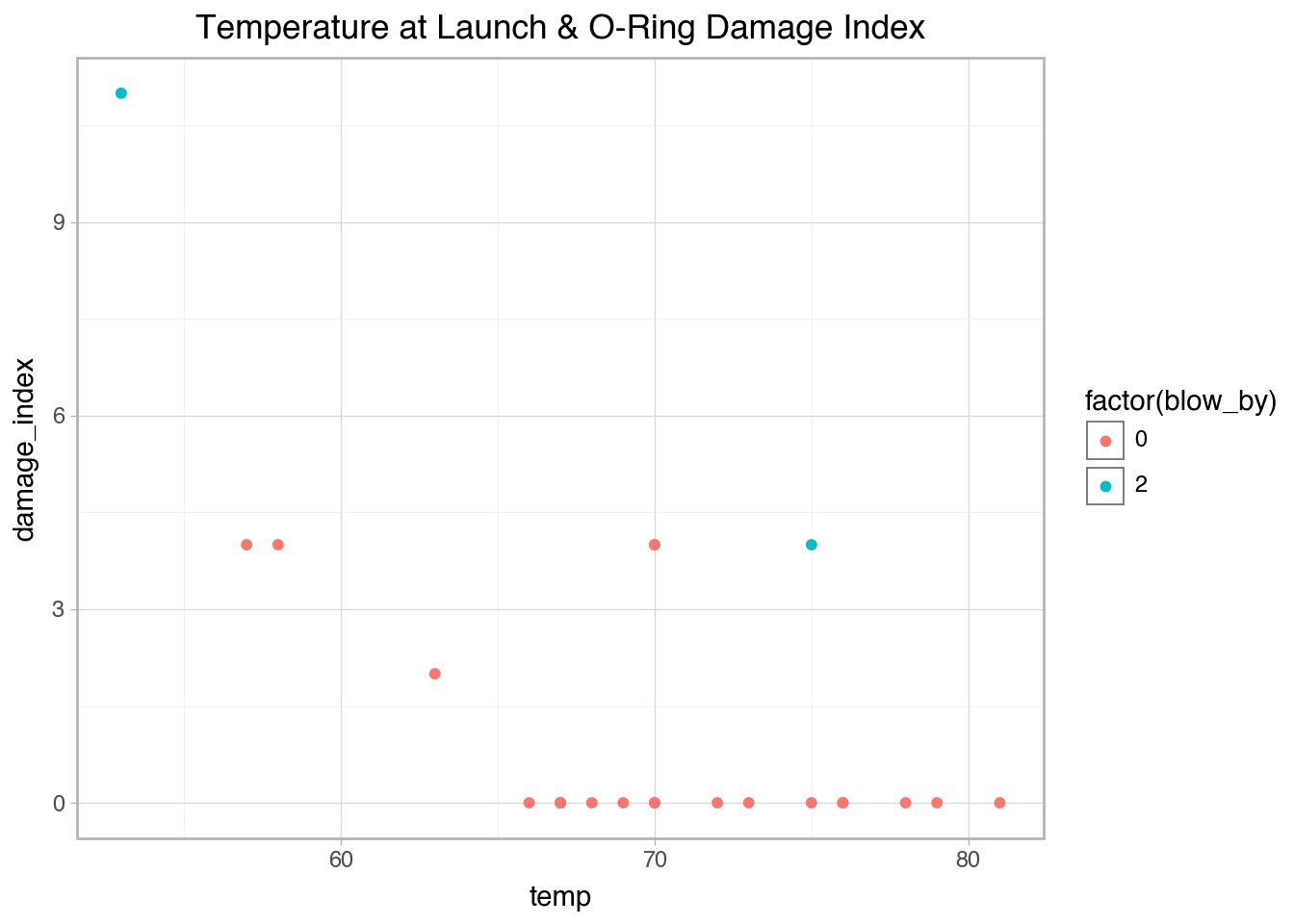
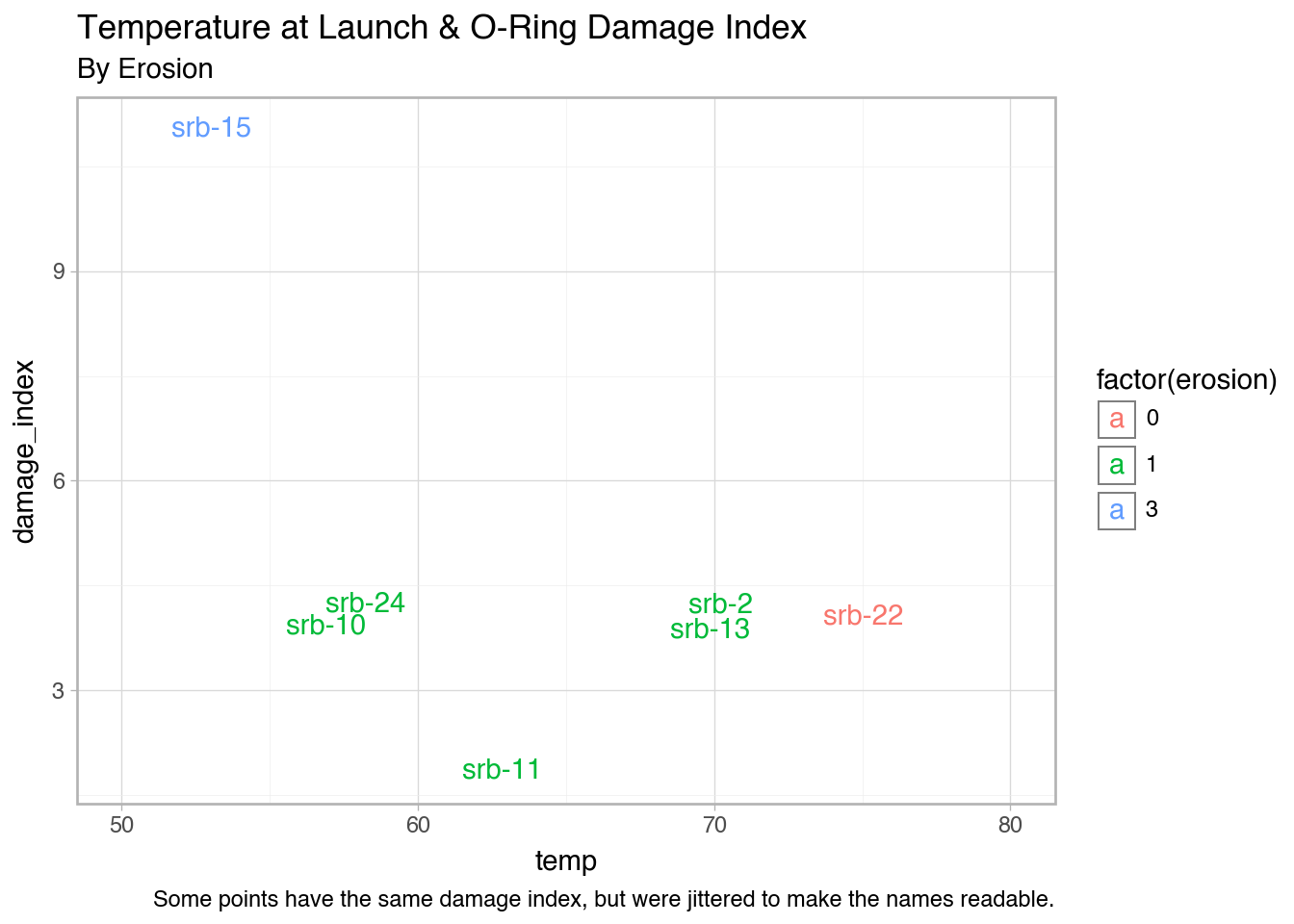
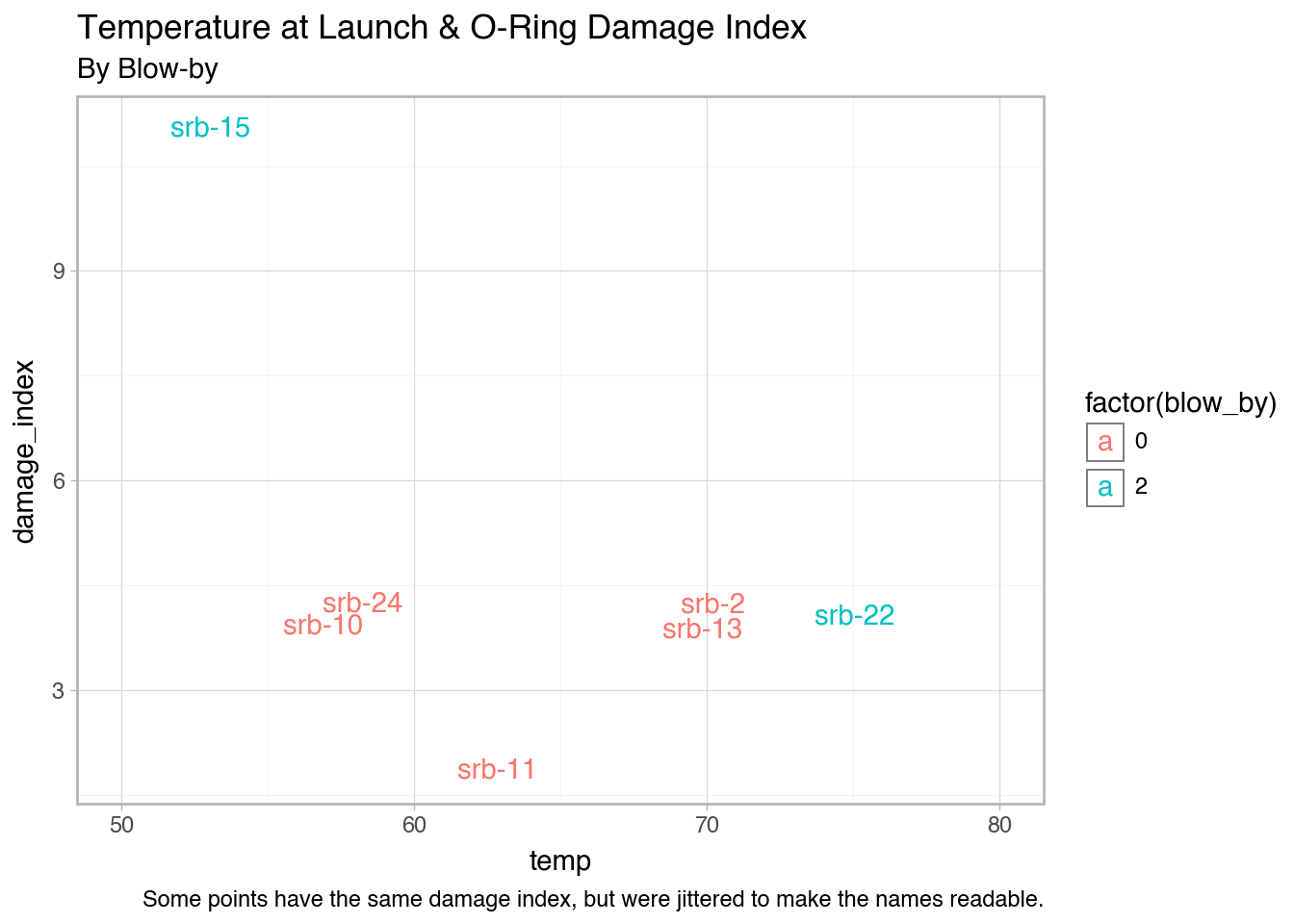
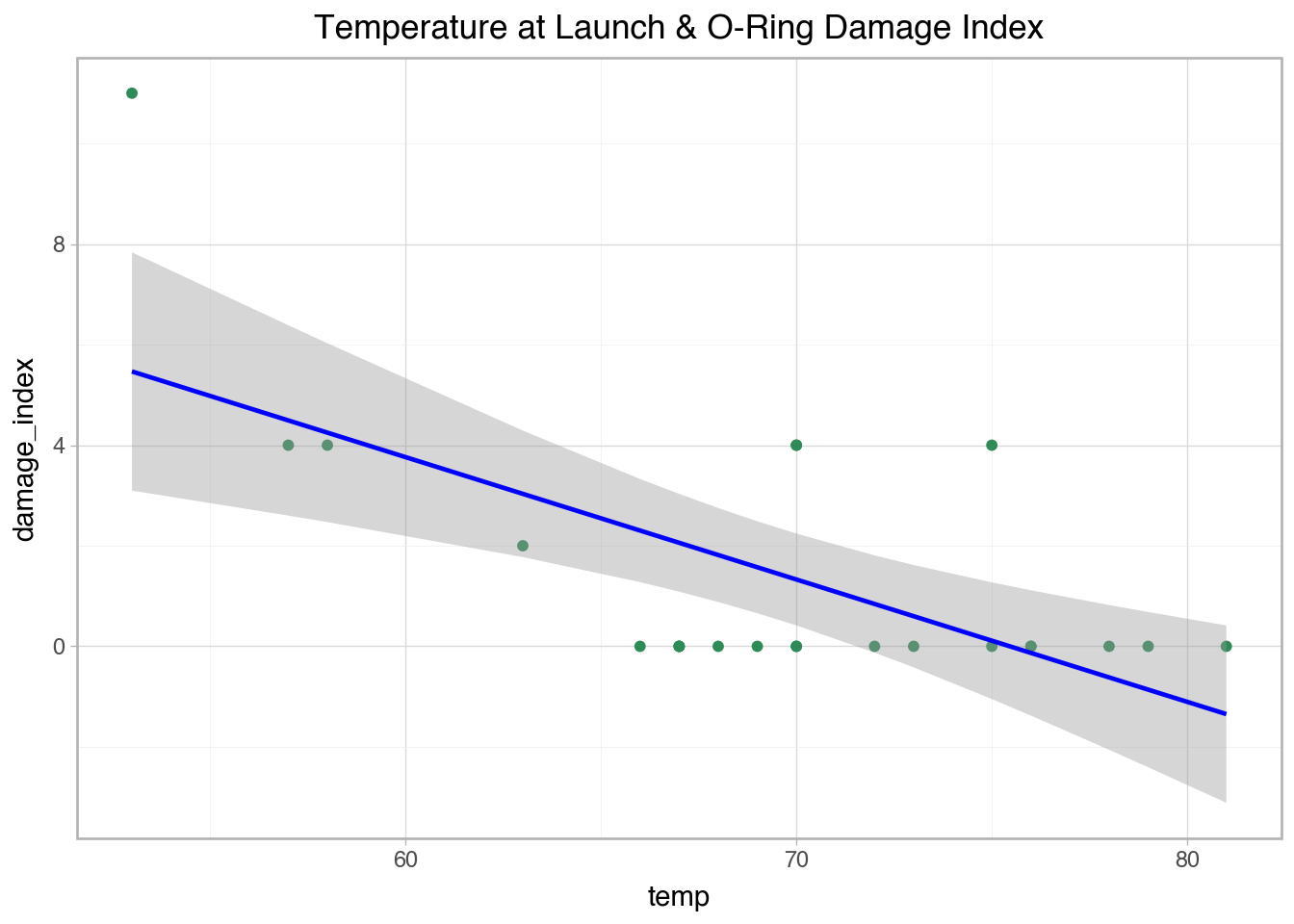
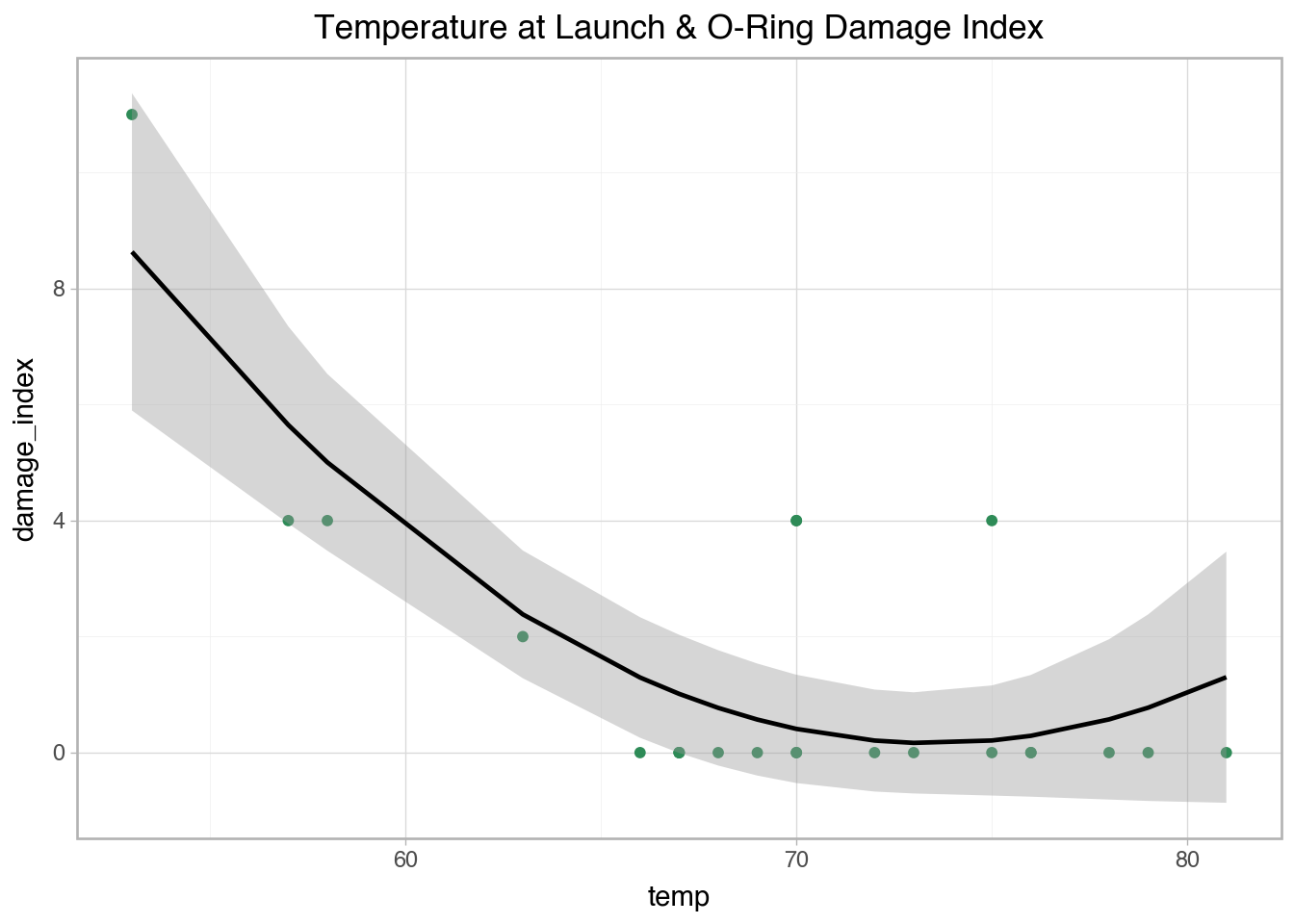
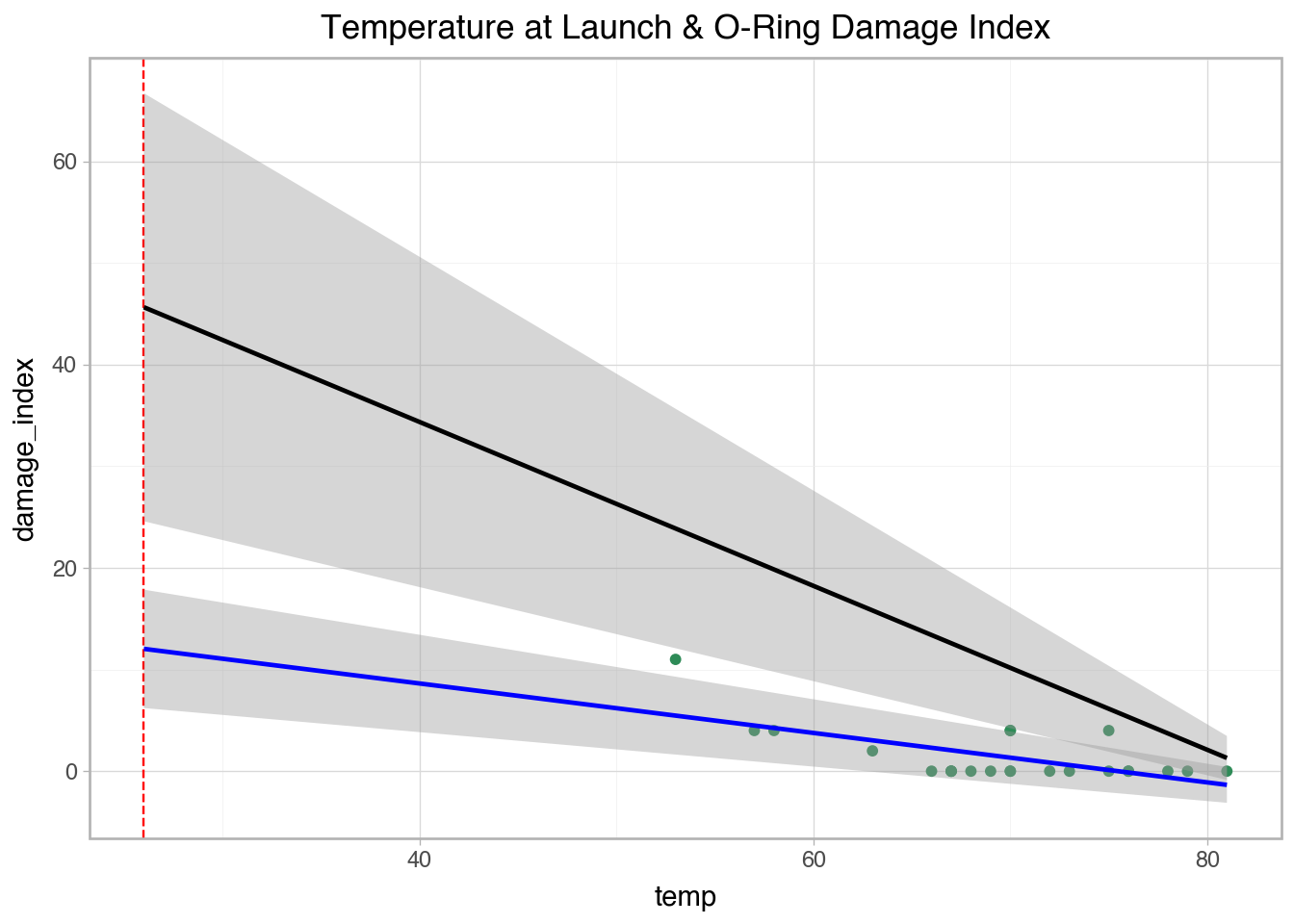
'temp': [53, 57, 58, 63, 66, 67, 67, 67, 68, 69, 70, 70, 70, 70, 72, 73, 75, 75, 76, 76, 78, 79, 80, 81],
'erosion': [3, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'blow_by': [2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0],
'damage_index': [11, 4, 4, 2, 0, 0, 0, 0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4, 0, 0, 0, 0, np.nan, 0],
'comments': ['Most erosion any flight; blow-by; back-up rings heated', 'Deep, extensive erosion', 'O-ring erosion on launch two weeks before Challenger', 'O-rings showed signs of heating, but no damage', 'Coolest (66 degrees) launch without O-ring problems', np.nan, np.nan, np.nan, np.nan, np.nan, 'Extent of erosion not fully known', np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, 'No erosion. Soot found behind two primary O-rings', np.nan, np.nan, np.nan, np.nan, 'O-ring condition unknown; rocket casing lost at sea', np.nan]})
space['date'] = pd.to_datetime(space['date'])
space = space.sort_values('date', ascending = True)
space['srb_num'] = ['srb-1', 'srb-2', 'srb-3', 'srb-4', 'srb-5', 'srb-6', 'srb-7', 'srb-8', 'srb-9', 'srb-10', 'srb-11', 'srb-12', 'srb-13', 'srb-14', 'srb-15', 'srb-16', 'srb-17', 'srb-18', 'srb-19', 'srb-20', 'srb-21', 'srb-22', 'srb-23', 'srb-24']
space.head()